

昨今、私達はたくさんの種類や量のデータを扱えるようになってきました。これまで主流であったアンケート調査などの標本調査データ(集めるデータ)だけでなく、WebアクセスログやSNSデータ、位置情報、スマートデバイスのデータなど、デジタルを通じて自動的に集まる、細かい粒度の大規模なデータ(集まるデータ)もビジネスに活用できるようになっています。
さらに、それだけでなく、データの分析方法も進歩しています。AIやデータサイエンスはこれまでならば一部のエンジニアや統計家が使うものだったかもしれません。しかし、今ではより多くの人にとって、それらはますます身近なものになっています。
つまり、現代のビジネスでは「リッチな情報を持つ大規模なデータ」を、「誰でも簡単に、半ば自動的に分析できる」ようになってきたと言って良いかもしれません。
しかしながら、こうした今だからこそ、少し立ち止まって考えなくてはいけないことがあります。
● そのデータは誰を対象にして得たのでしょうか?
● どういう指標をどのように測定しているのでしょうか?
「大規模なデータを自動的に分析できる」というのは聞こえが良いですが、データを扱う人にとっては、データそのものも、分析方法もどんどんとブラックボックス化しやすくなっています。このことをよく考えないで、データの量を盲信したり、AIが出した結果を鵜呑みにしたりしていると、ビジネスの判断を間違える恐れがあります。
例えば、こんな問題を考えみましょう。
| 毎年恒例の音楽番組のテレビ視聴時間を比較します。 ・男性の平均視聴時間は、2017年が2018年より5分長かった ・女性の平均視聴時間も、2017年が2018年より5分長かった さて、全体の平均視聴時間が長かったのは2017年と2018年どちらでしょうか? |
男性も女性も2017年で視聴時間が長いわけですので、普通に考えると全体の視聴時間は2017年の方が長いように思います。
しかし、このときの結果は「2018年の方が長い」でした。
なぜこのようなことが起きるのでしょうか。実は、以下の表のようなカラクリがあります。
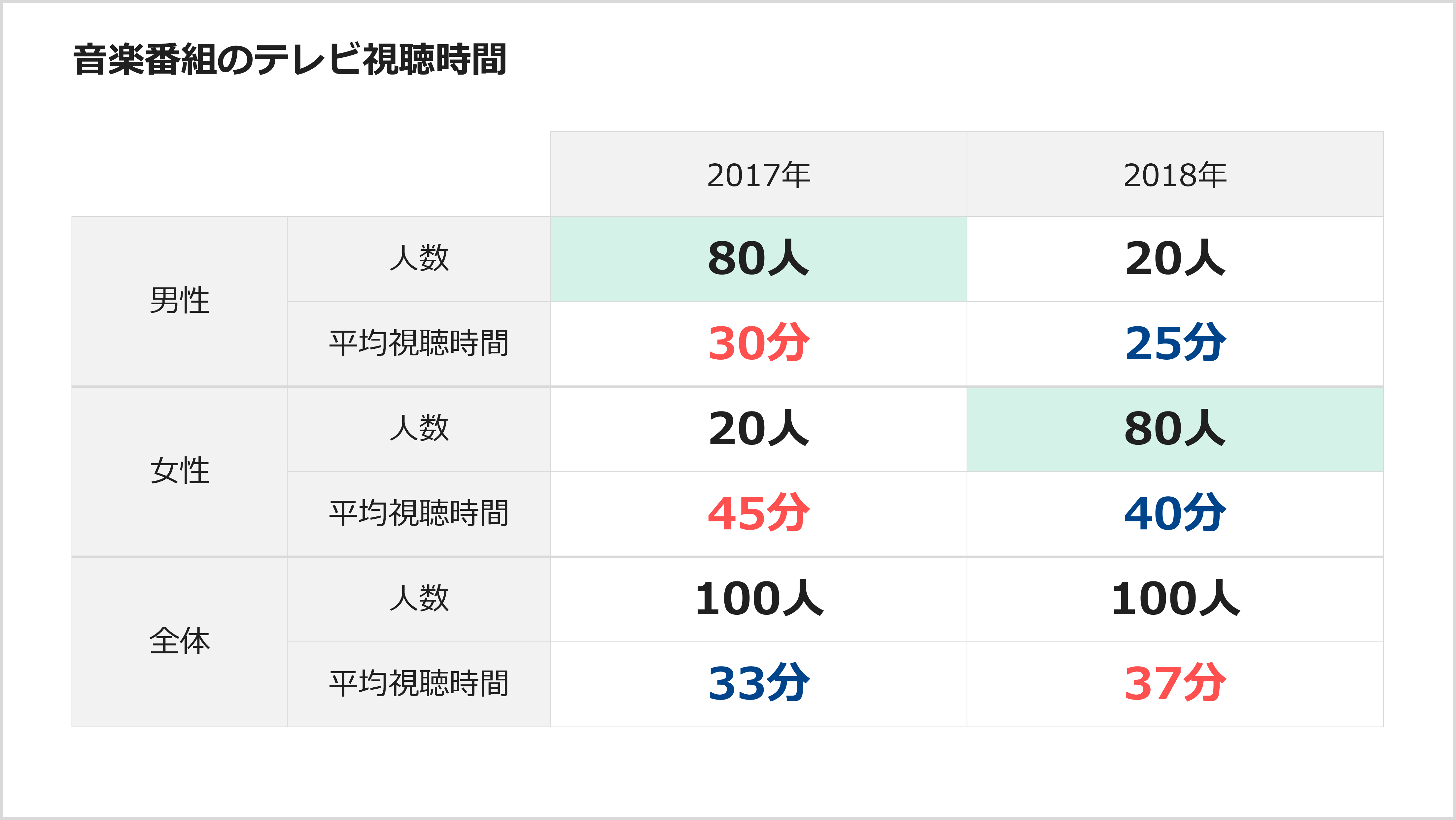
この表をみるとわかるのは、
① 男性よりも女性で平均視聴時間が長い
② 2017年は全体の8割が男性に対して調査しているのに対して、2018年は全体の8割が女性に対して調査している、
ということです。言い換えると、男女の視聴傾向が異なるにも関わらず、男女の構成比が違う調査結果から全体を捉えて、比べてしまったということです。すると、不思議なことに全体の視聴時間では2018年の方が長くなるという現象が起きます。
この問題は「シンプソンのパラドックス」と呼ばれる統計学の有名な問題です。これは一つの例に過ぎませんが、データの中身をよく見ないで判断すると、傾向を読み間違えてしまうことは、これ以外にも頻繁に起こりえます。
そして、往々にして、こうしたことはビッグデータなどの少し偏ったデータだとよく起こりがちです。
それでは、私達はどのようにしてデータと向き合い、理解を深めていけば良いのでしょうか。その術を知っていくことは、様々なビジネスデータ活用において有用です。
ここではそのポイントを2点あげます。
第1に、データの設計を知り、正しくデータを評価すること、
第2に、データが偏っていたのならば、その偏りを補正して使っていくこと、です。
データを評価するときには、まず、その設計を知る必要があります。古典的な標本調査法における設計とは以下のようなものです。目的と指標を定義し、母集団を決め、そこから調査対象を抽出し、データを測定し、分析すること。この一連のプロセスを「調査設計」と呼びます。

この調査設計の考え方は、標本調査法によるデータに対するものですが、他の様々なデータ(例えば、昨今のビッグデータ)を理解するときにも応用していくことができます。
この考え方を使って、データを評価していくと、まずは大きく分けて、以下の2点を明らかにしていくことができます。
①そのデータが説明している範囲:カバレッジ
➁データ内の偏り
例えば、インテージの消費者パネルSCI では、カバレッジとして、対象者:全国15歳~79歳の男女、対象カテゴリー:食品、飲料、日用雑貨品、化粧品、医薬品、タバコ(ただし、食品は、生鮮・惣菜・弁当を除く、家庭内消費に限らず、屋外消費を含む、バーコードが付与された商品のみ)という定義をしています。このような定義をきちんと行うことによって、そのデータがどこまでの範囲を説明するものなのかを明確にすることができます。
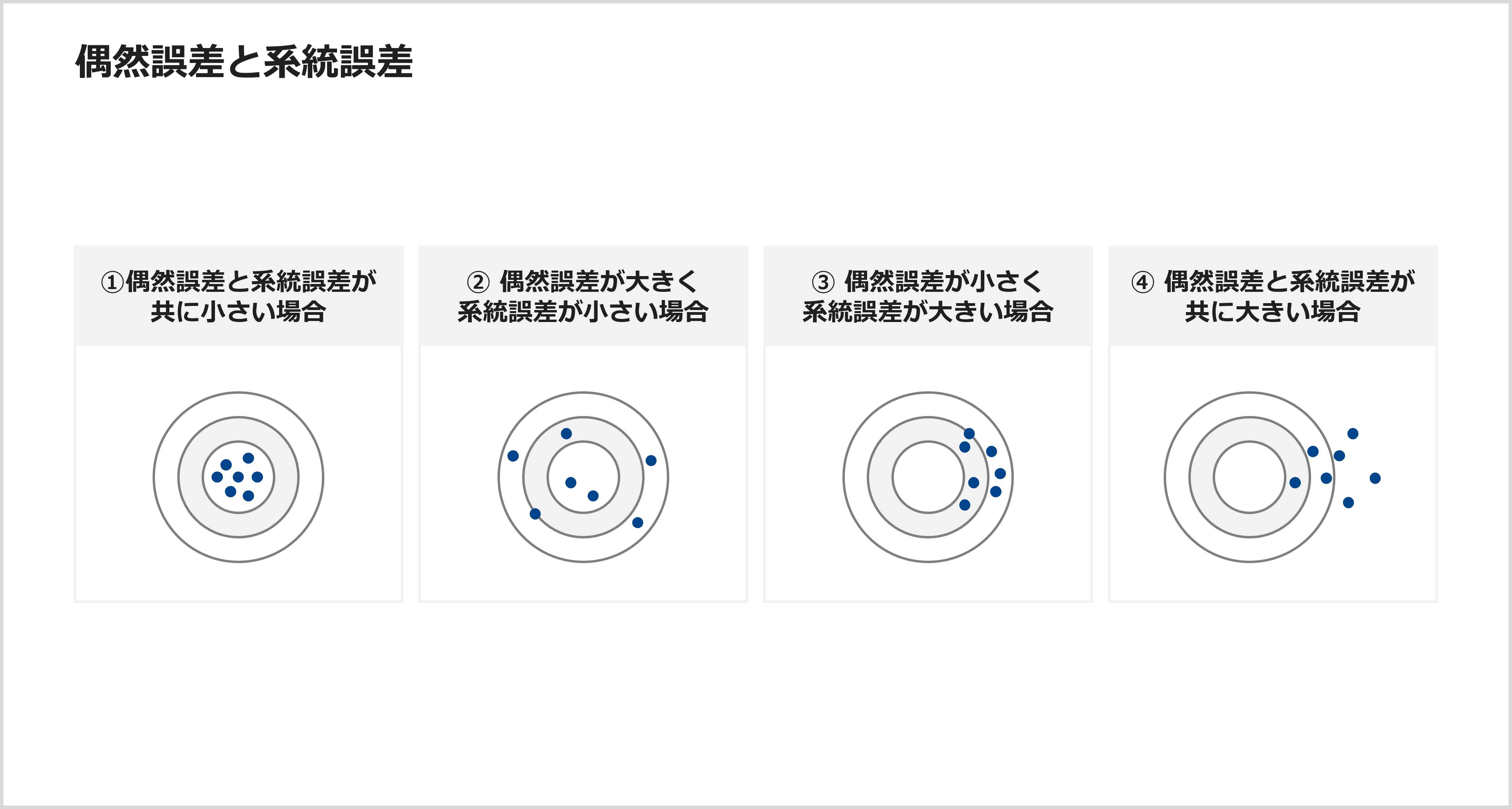
さらに、カバレッジを規定すると、その中でのデータの偏りを評価していくことも可能になります。偏りには、大きく分けて、偶然誤差と系統誤差という2種類があります。偶然誤差というのは、データ収集時の偶然がもたらす値のばらつきです。一般的に、調査対象者の数が少ない場合(サンプルサイズが小さい場合)や測定回数が少ない場合に、偶然誤差は大きくなります。逆に言えば、調査対象者数や測定回数を増やしていけば、改善できるのが偶然誤差です。
しかしながら、いくら調査対象者数や測定回数を増やしても改善できない誤差があります。それは、特定の収集対象者の性質や測定方法の原因によって生じる偏りです。これを系統誤差と呼びます。
例えば、冒頭に挙げた男女のテレビ視聴傾向差のように、男性と女性でデータの性質が違うとします。このときに、男女比が目標としたい母集団の構成比と異なっていると、系統誤差によって、全体のデータ傾向が本来捉えたいものとは違ってきてしまうことがあります。
よく誤解しがちなのは、“サンプルサイズが大きければ、「誤差」は小さくなる”という考え方です。偶然誤差については、たしかにサンプルサイズが大きければ小さくなります。しかし、系統誤差はサンプルサイズをいくら増やしても改善されません。男性と女性で性質が違うのに、男性だけのデータをいくら多く集めても、本来目標とする対象を説明することはできないということになります。“ビッグデータだから正しい”わけではない理由がここにあります。
では、偏りがあるデータは、役に立たないのでしょうか?
そんなことはありません。適切な補正をすれば、十分に使えるようになることがあります。むしろ、そういったチャンスをいかにモノにしていくかが、昨今の様々なデータを扱えるビジネス環境では重要かもしれません。
データの補正にはいくつかの方法があります。
例えば、調査で何らかの指標の値を集計する場合、収集対象者の系統誤差を補正する方法として、よく用いられるのが「ウェイトバック集計」です。ウェイトバック集計は、系統誤差が生じていて、かつ、母集団の人口構成比とデータの構成比が異なっている場合に有効な補正方法です。これにより、母集団の構成比に即した集計値が算出可能になります。
アンケート調査の方法とコツ④ アンケート結果のまとめ方・集計の基本とコツ
また、少し話は難しくなりますが、施策の効果を捉える場合に使える補正技術として、「統計的因果推論」と呼ばれるものがあります。ここでいう施策の効果とは、例えば、テレビCMを流した結果、Webサイトにどれくらい人が流入したかを捉える場合などを指します。あまり深く考えずにやると、CM接触者と非接触者で、サイト流入率の差を比べて、それをCMの効果としがちです。しかし、CM接触者と非接触者の間に偏りがある場合、実はこの効果の推定がうまくいかないことがあります。そんな時に、統計的因果推論を使うと、この偏りを補正して、施策の効果を正しく推定することができます。統計的因果推論は、2021年のノーベル経済学賞でも大変話題になり、近年注目されている技術の一つです。詳しくは、こちらを御覧ください。
R&Dセンター
https://www.intageholdings.co.jp/rd/blog/academicprograms/contents201901281400.html
様々なデータのクセを見抜いて、使えるようにしていく素養は、現代のデータ活用環境において非常に重要になっているように思われます。
i-college「統計的データ理解講座~データの設計・偏り評価・因果推論入門~」では、今回ご紹介した「データを評価する」「偏りを補正する」ことについて具体的に紹介しています。興味を持ってくださいましたら、ぜひご参加ください。
インテージのデータ解析・予測サービス
最新のデータサイエンス技術と独自データを活用し、予測や最適化シミュレーションなど高度なデータ活用を実現します。

◆本レポートの著作権は、株式会社インテージが保有します。
下記の禁止事項・注意点を確認の上、転載・引用の際は出典を明記ください 。
「出典:インテージ 「知るギャラリー」●年●月●日公開記事」
◆禁止事項:
・内容の一部または全部の改変
・内容の一部または全部の販売・出版
・公序良俗に反する利用や違法行為につながる利用
・企業・商品・サービスの宣伝・販促を目的としたパネルデータ(*)の転載・引用
(*パネルデータ:「SRI+」「SCI」「SLI」「キッチンダイアリー」「Car-kit」「MAT-kit」「Media Gauge」「i-SSP」など)
◆その他注意点:
・本レポートを利用することにより生じたいかなるトラブル、損失、損害等について、当社は一切の責任を負いません
・この利用ルールは、著作権法上認められている引用などの利用について、制限するものではありません
◆転載・引用についてのお問い合わせはこちら






