

この【データサイエンスを知るコラム】は、インテージのデータサイエンティストが、最新技術やマーケティングへの活用可能性などを解説するコラムです。
第2回はシニアデータサイエンティストの伊藤友治がAIを用いた自動販売機の画像解析について、事例を元に解説します。
こんにちは、インテージ先端技術部の伊藤です。インテージデータサイエンティストによるエキスパートコラムの第二弾として、マーケティングサイエンスの領域から最近取り組んだ事例のご紹介をしていきます。弊社は主にマーケティングリサーチ事業をしている会社ですが、近年ではディープラーニングのようなAIをマーケティングやリサーチ課題の解決にうまく活用できないかと日々模索しております。その中でも今回は急速に発展してきている画像解析の領域にフォーカスして、取り纏めていきたいと思います!
今回は具体的な取り組み内容の一例として、屋外の自動販売機に関する調査の効率化に向けたアプローチをご紹介していきます。ちなみに画像解析には大きく分けて分類と検出の2種類があるのですが、今回は主に物体が写っている領域の検出と、その検出した物体の分類を行う目的で進めております。
従来の自動販売機の調査は、調査員が担当エリアを巡ってどこのメーカーの、何の商品が、どれだけあるか、を一つ一つ目視で調べてきました。1台の自動販売機には30~40個の商品が並んでいるため、どこに何の商品があるのかを書き残していくことを考えると結構時間がかかりそうですよね。ただ、画像に何の商品が写っているかを調べるのであれば、そこはまさにディープラーニングの得意分野であり、自動化できれば工数の省力化に繋がるはずです。調査員の代打をつとめるためには、自動販売機のどこに、何の商品があるかを画像認識して出力することができればOKです。弊社ではこれらの工程を一般物体認識と特定物体認識という2種類のスキームに分け、データ収集からモデル作成、検証までを進めてきました(Fig. 1)。それぞれの役割は、一般物体認識では物体のカテゴリー特定およびその位置を検出し、特定物体認識では一般物体認識で検出した物体の正体を突き止めていくという要領です。

Fig. 1 一般物体認識と特定物体認識
どこに、どんなカテゴリーの物体があって(一般物体認識)、その物体は何なのか(特定物体認識)の順で、物体を認識させるモデルを構築していきます。
一般的に画像解析をする上では、CNN※1という画像内の物体の特徴を捉えるネットワークを使うことが多いですが、何百何千という学習データが必要になると言われています。もちろん、認識したい物体によっても変化するため、実際にはやってみないと何ともいえませんが。。。さて、そんな学習データですが、一般物体認識と特定物体認識のそれぞれで使うデータが少し違います。まず一般物体認識では、商品をペットボトルや缶、瓶といった大まかなレベルでラベル付けした自動販売機の画像データ全体を使用しています。一方、特定物体認識では、個別レベルの商品をターゲットにするのですが、意外と数を稼げないレアな商品も多く、数百台くらい集めても数個しかないものもありました。このフェーズでは、自動販売機の画像データから個別の商品画像を切り取ったものを使用しています。後述では、一般物体認識と特定物体認識の二つに分けて、どのようにアプローチしたかご紹介していきます。
画像解析に用いるCNNにも様々な種類があり、用途に合わせて使用するモデルを選ぶ必要があります。今回使用したモデルはSSDというディープラーニングモデルで、一つの画像のなかに複数の物体があっても、物体検出の精度が良いという特徴があります。他にも似たようなモデルとして、R-CNN系やYOLO系も挙げられますが、学習時間や物体検出の精度を比べたところ、今回はSSDを選ぶことにしました。肝心の学習データは、自動販売機の写真を数百枚ほど地道に集めていき、Annotation※2という作業を経て、商品画像データを準備しました。
ディープラーニングを使ったモデルを構築する際は、学習済みのパラメータを初期値としてモデルを構築することが多いです。ここで言っている学習済みパラメータとは、既存のある分野の画像データを元にして学習させたパラメータのことで、このパラメータを初期値として使うと学習するデータが少なくても学習させることができます。なぜ学習がうまくできるのかは不明な部分もあるようですが、どうやら分野が異なっても、物体の特徴を捉えるという能力を流用できる部分があるのでは?と言われています。ちなみに本当に学習済みパラメータが大事なのか気になったので試してみたところ、これを使わないで認識させても確かにうまく物体検出をしてくれませんでした(Fig. 2)。

Fig. 2 学習済みパラメータを使用していない場合
学習済みパラメータを初期値として使わないで商品を学習させた結果です。全体的にうまく検出できていないことがわかります。
Fig. 2の結果を踏まえ、今回は学習済みパラメータを初期値として内包したモデルに対して、新たに自動販売機の画像データを学習データとして学習させることで、より検出精度を高めていきました(Fig. 3)。ちなみに学習済みパラメータはImageNet※3という画像DBで学習したパラメータを使用することにしましたが、確かに物体検出の精度はあがっていそうです。
ただ、光が反射した画像や明暗の大きい画像は検出できないこともあったため、撮影画像のクオリティはとても重要そうです。屋外の自動販売機が対象ですので、撮影方法や時間帯、機材の選定等のデータ品質を揃える工夫もしていくことで、物体検出の精度を向上させることはできると思います。幸いにして?私はカメラが好きなので、その辺の検討も含めて頑張りたいところです。

Fig. 3 学習済みパラメータを初期値として学習データを学習させた結果
学習済みパラメータを用いて学習させるといい感じに物体検出してくれました。物体のサイズもペットボトルや缶などバラバラですが、画像データを与えるだけで物体の位置以外にもサイズの矩形推定もできていそうです。ディープラーニング、すごいですよね。
一般物体認識でどこに商品があるかは検出できたので、今度はその商品の正体を突き止めていきます。自動販売機にある商品って結構たくさんありますよね?よく目にする商品だけを数えてみてもざっと100種類以上はあるのですが、数百台の自動販売機の画像を集めても数個しかない商品もあるため、如何に少ないサンプル数でも認識精度を確保できるかが重要になりそうです。そこで今回はmetric learning※4の一種である、siamese networkを使って商品特定できるかを試していくことにしました(Fig. 4)。siamese networkは少ない学習データでも物体を特定できる特徴があるため、学習データをあまり多く用意できない本件に適しているはずです。
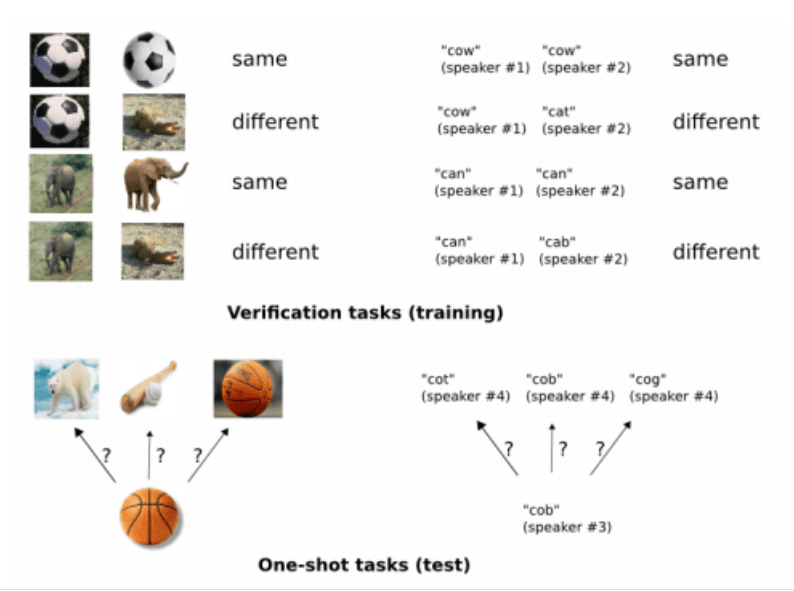
※https://www.cs.cmu.edu/~rsalakhu/papers/oneshot1.pdf
Fig. 4 siamese networkの概念図
様々な組み合わせの画像をランダムに組み合わせて、同じ画像であればsame、異なればdifferentとして学習させていきます。ここでも学習済みパラメータを初期値として用いることで、画像の特徴をある程度は捉えることができる状態で学習を進めることができます。
学習データは自動販売機の各商品の画像を一枚ずつ手動で切り出してきたものを使用し、それをdata augmentation※5で水増しして学習を進めました。結果的には100種類程度の商品を学習させ、誤認識率は数%程度に抑えることができるようになりました。単純な精度以外にも、t-sne等の手法で学習結果を2次元空間へマッピングすることで、商品同士がどのような位置関係にあるかを視覚的にも確認してみました(Fig. 5)。全体的な傾向としては、似たカテゴリーの商品は近い位置にマッピングされているため、学習の結果は概ね問題ないと判断しました。
それではなぜ数%の誤認識が発生したのでしょうか?間違えた商品の画像をチェックしていくと、撮影した画像データに明暗やブレ、ボケがあるものが多くありましたので、単純に写真が綺麗に撮れていないことが一因のようです。他にも商品に付属しているPOP広告が、同じ商品でも有るもの無いものがあるせいで、学習データにはPOP広告がついているが、検証データにはなかったというケースもありました。画像データの明暗やブレ、ボケ等のクオリティ問題は一般物体認識でも同様の問題でしたが、特定物体認識の場合では個別商品の見た目のバラエティさも予め把握しておく必要がありそうです。

Fig. 5 商品間の類似性をt-sneで2次元空間へマッピング
似た商品は近い位置に配置されるようになっており、左側はコーヒー系が、右側には清涼飲料系が、真ん中にはお茶系がまとまっていることがわかります。基本的にはなんとなく見た目が似た商品は近い位置にマッピングされているため、人の認識と近い形になっていそうです。
自動販売機のように多量の物体が写っている画像から物体の検出と特定をするケースについてざっくりと取り纏めてみましたが、如何でしたでしょうか?今回はまず物体の位置を検出し、その検出した物体を特定するという2つのフェーズに分けることで、自動販売機の画像に何が写っているかをある程度は自動で判別することができるようになりました。こういった実応用例は多くありませんが、どこに落とし穴があるかはその分野のドメイン知識がないとなかなか見抜けないこともあるため、なるべくその分野に明るい人材と一緒に仕事することが最良です。そういった意味では弊社も一日の長がありますので、ご興味のある方がいらっしゃいましたら一緒にお仕事をさせていただければ幸いです!
ただ、ディープラーニングのようなAIを導入して効率化をはかる場合、既存の人件費に対して導入コストが下回らないと意味がありません。そのため、従来の工数(データ収集と人手によるチェック)と新たに発生するAI費用(モデル開発や維持)のそれぞれを試算した上で、本当に費用削減効果があるのかは把握しておきたいところです。また、AIを導入する目的がコストを意識したオペレーションの効率化ではなく、人に依存しない安定的な業務遂行を目指した業務の標準化に重きを置く場合もあるかもしれないため、利用するシーンに応じて考え方を決めておくことは肝心です。まぁそうは言っても、往々にして両方とも求めるケースが多いはずですので、事前に発生しうる誤差を理解した上で、品質的に使用できるかどうかを検討していく方が健全ではないでしょうか。例えば、自動販売機市場の中で、あるエリアの自社製品の棚シェアを知りたいときに、コストを10%圧縮することができそうだが誤差率は2~3%あることがわかっている。果たしてこれは導入すべきかなのか?はお客様によって判断が分かれるところかもしれません。
弊社で所謂AIを活用した取組事例のご紹介は以上になりますが、国内外も含めてこういった事例は多くないため、今回の取組方法を初めて耳にされた方もいるかもしれません。ただ、確実にマーケティング分野の取組事例は増えてきており、先日開催されたMIRU2019という画像とAIにおける国内最大級のシンポジウムでも、マーケティング系の話題でディープラーニングを活用した事例がいくつか紹介されていました。私自身もインテージというマーケティングリサーチの会社にいるおかげで、マーケティングに関わる案件に携わる機会が多いですので、この界隈の話題については今後も注目していきたいところです。
※1:CNN
Convolutional Neural Networkの略。人間の視覚野の構造からアイデアを得て作られたニューラルネットワーク。特徴量の畳みこみを行うConvolutional Layerと情報の抽出を行うPooling LayerをNeural Networkに導入したもので、上下左右を加味した特性を扱うことができます。画像を扱う問題で利用されることが多いです。
※2:Annotation
画像データや音声等の非構造化データに対して、そのデータが何を表しているかをタグ付けする作業のことを指します。画像データ全体に対してタグ付けするものや、画像データ内の一部分を矩形で囲ってタグ付けするものもあります。
※3:ImageNet
1,400万枚以上の画像にクラス名が付与されている画像データベース。
ImageNetのデータセットを題材とした画像判別のコンペティションILSVRC(ImageNet Large Scale Visual Recognition Challenge)が毎年開催されており、近年のCNNの目覚ましい発展はその結果から見て取れます。画像分類のベンチマークとしてよく使われています。
※4:metric learning
距離学習とも言われるもので、顔認識や物体の同定などに用いられる手法の一種です。
※5:data augmentation
学習データを水増しすること。画像のdata augmentationでは、角度を変えたり、左右を反転させたり、輝度を変えたりする手法がよくとられます。
インテージのデータ解析・予測サービス
最新のデータサイエンス技術と独自データを活用し、予測や最適化シミュレーションなど高度なデータ活用を実現します。
◆本レポートの著作権は、株式会社インテージが保有します。
下記の禁止事項・注意点を確認の上、転載・引用の際は出典を明記ください 。
「出典:インテージ 「知るギャラリー」●年●月●日公開記事」
◆禁止事項:
・内容の一部または全部の改変
・内容の一部または全部の販売・出版
・公序良俗に反する利用や違法行為につながる利用
・企業・商品・サービスの宣伝・販促を目的としたパネルデータ(*)の転載・引用
(*パネルデータ:「SRI+」「SCI」「SLI」「キッチンダイアリー」「Car-kit」「MAT-kit」「Media Gauge」「i-SSP」など)
◆その他注意点:
・本レポートを利用することにより生じたいかなるトラブル、損失、損害等について、当社は一切の責任を負いません
・この利用ルールは、著作権法上認められている引用などの利用について、制限するものではありません
◆転載・引用についてのお問い合わせはこちら






