

この【データサイエンスを知るコラム】は、インテージのデータサイエンティストが、最新技術やマーケティングへの活用可能性などを解説するコラムです。
インテージデータサイエンティストによるエキスパートコラム第3弾は、「消費者セグメンテーション」をテーマにご紹介します。
行動データに基づく消費者セグメンテーションは、企業が蓄積および利用できる消費・購買データ量が増加するにしたがって重要性を増しています。データに基づく1 to 1アプローチが可能になった現在、マーケティング施策への消費者の反応を高めるには、セグメンテーションおよびターゲット層を精度高く規定することが鍵といえます。また、ターゲット層を決めた後に、マーケティング施策内容を考えるうえで、多面的にターゲット層をプロファイルすることを通じて実態を深く理解し、施策のコンテンツを企画・実行することが求められます。
今回は高精度なセグメンテーションの方法として「トピックモデル」を取り上げ、プロファイル分析と組み合わせた多角的な視点でターゲット層を捉える方法をご紹介します。
セグメンテーションを統計的なアプローチに基づいて行う際、従来はタンデムクラスタリングを行うことが主流でした。タンデムクラスタリングは次元縮約(※1)とクラスタリング分析を組み合わせた手法です。
クラスタリングでは、対象間同士の距離から計算した類似性をもとに分類を行います。しかし、クラスタリングに使う変数の数が多くなると、計算の都合上距離が急速に大きくなってしまい、似た特徴同士の対象をうまくまとめることができなくなってしまいます。すると、「どの対象も似ていない」という結果になり、意味のある解を得られなくなってしまうのです。そこで、変数が多くても距離の計算ができるように、次元縮約を使って情報を圧縮し、変数をいくつかのカテゴリーにまとめます。これにより、距離が大きくなってしまう現象を防ぎ、クラスタリング分析の類似計算ができるようになります。
ただし、この方法では次元縮約とクラスタリング分析はそれぞれ独立して実行します。このため、クラスタリングで対象を最も精度高く分類できるような次元縮約が行われているとは限らず、本来であれば似ていないデータ同士が同じクラスタに分類されてしまうなど、解釈をしにくいクラスタ構成になる可能性があります。これでは、精度が高いクラスタリングが実現できません。
このような問題点を補う方法として、今回はトピックモデルを取り上げます。トピックモデルは元々文書データに適用される手法であり、文書が複数の潜在的なトピックから確率的に生成されることを仮定したモデルです。この方法では、図表1上段のような行列データを使用します。行は文書、列は文書に含まれる単語であり、各セルには文書ごとに出現する単語の頻度が入ります。このようなデータはBoW(Bag of Words)形式と呼ばれます。トピックモデルでは、この行列データの行の要素と列の要素の背後にある共通の特徴を潜在トピックとして抽出します。
図表1
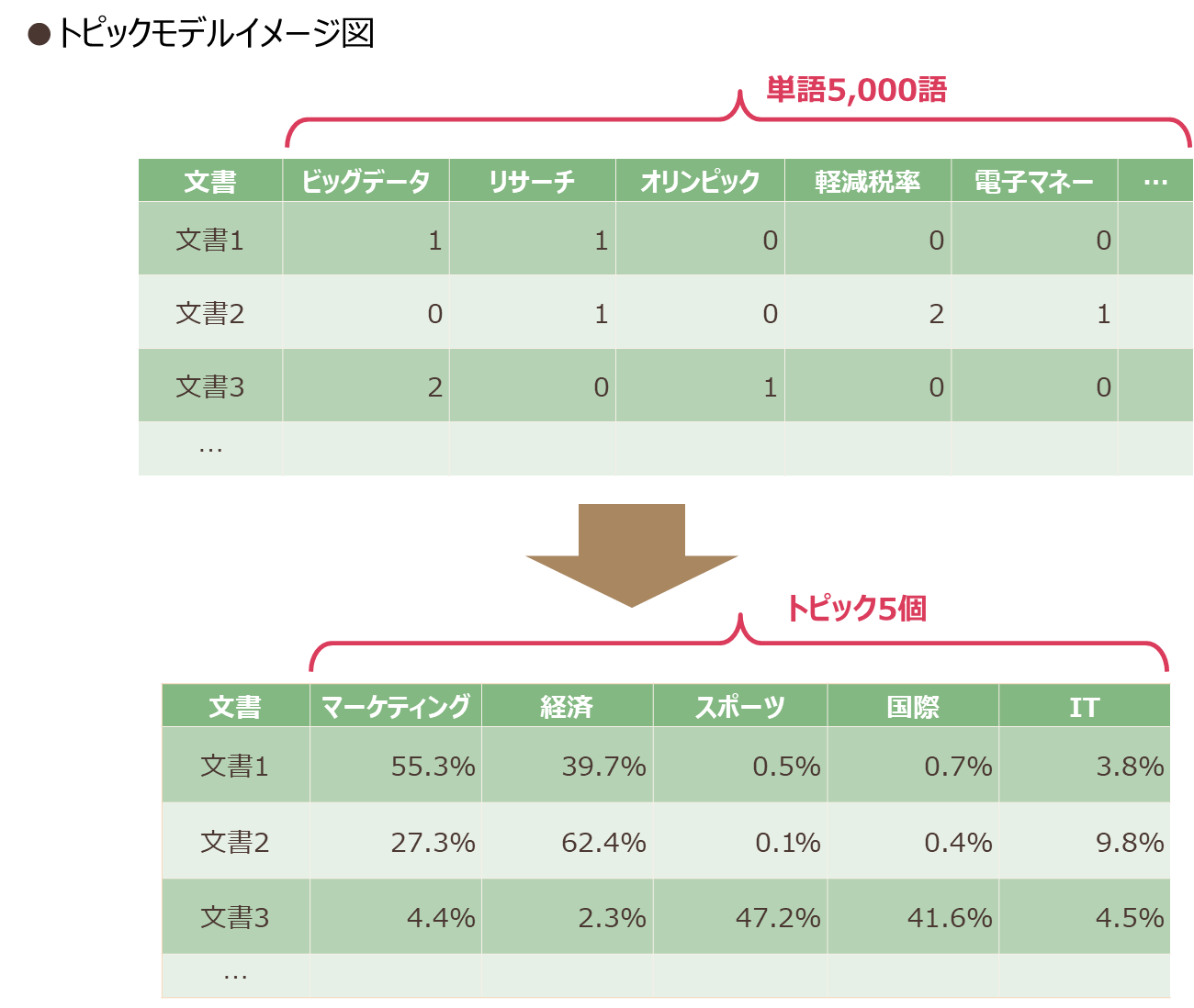
トピックモデルのアプローチは、タンデムクラスタリングの次元縮約とクラスタリングを同時に行う方法に近いといえます。図表1を見ると、列数が5,000だったデータを、5つのトピックで表しています。これは次元縮約に相当します。一方、文書を各トピックに分類する点は、クラスタリング分析に相当します。このようにタンデムクラスタリングとは異なり、トピックモデルでは2つの手法をスムーズにつなげて実行しているといえます。
また、トピックを確率的に計算することで、行と列の各要素の所属確率を示せることもトピックモデルの大事なポイントです。つまり、1文書につき1トピックではなく、複数のトピックにまたがる可能性を考慮しているのです。このような考え方を、「ソフトクラスタリング」と呼びます。従来のクラスタリングは「ハードクラスタリング」と呼ばれ、データが1つのクラスタに完全に属するように分類する方法でした。一方ソフトクラスタリングは、データが複数のクラスタにまたがることを許容します。例えば図表1の例でいえば、「文書1は「マーケティング」トピックと「経済」トピックに所属する確率が高いから、複数のクラスタへの所属可能性を捉えることができる」と解釈できます。
以上から、次元縮約とクラスタリングをシームレスに行え、かつソフトクラスタリングにも対応している点は、トピックモデルの大きな利点といえるでしょう。
トピックモデルで使用できるデータは、文書データだけではありません。実際、図表1のようなBow形式を満たすデータであれば、トピックモデルを適用することができます。したがって、ID-POSデータのトランザクションデータをモニター×購入アイテム別の購入金額または頻度形式に展開し、購入意向に相当するトピックの抽出と、トピックへの所属確率に基づく消費者セグメンテーションを行うケースもあります。
トピックモデルによるトランザクションデータによるセグメンテーションは、上記の理由からタンデムクラスタリングに比べて「クラスタリングの精度を担保したトピック抽出」を行えます。つまり、「高次元のデータでも高精度な分類」と「ソフトクラスタリング」を同時に行える点で実務上の利点も高いといえます。とくに、セグメントに対してそのあとマーケティングアクションを実行する場合には、消費者の特徴を正確かつ多角的に把握することが必要です。よって、そのためにもクラスタリングの精度は重要となります。この点からも、セグメンテーションにおいてトピックモデルを適用することは望ましいといえるでしょう。
ここからは、トピックモデルを適用した事例をご紹介します。今回は弊社の購買ログデータSCIデータを使い、トピックモデルによるセグメンテーションのプロセスを見てみましょう。
トピックモデルにはいくつか種類があります。その中でも今回はPLSA(Probabilistic Latent Semantic Analysis)(※2)と呼ばれるモデルを適用します(他にもLDA(※3)などがあります)。PLSAは観測データから直接トピックを生成することができるため、データがもつ情報を反映させやすいという利点をもっています。この点を生かし、実際に分析してみます。
データはSCIの低アルコール飲料の購買履歴を使用しました。低アルコール飲料はサワー・チューハイ・ウィスキー・ハイボールなど種類が豊富で、様々な消費者のニーズや飲用シーンが想定できます。また、このカテゴリーは女性飲用者も多い市場でもあります。そこで、今回は「女性はどのような低アルコール飲料商品を選好して飲用するのか」を探索します。商品の購買傾向で消費者をセグメンテーションし、女性購買者の含有率が多いセグメントを特定してその特徴を把握していきます。
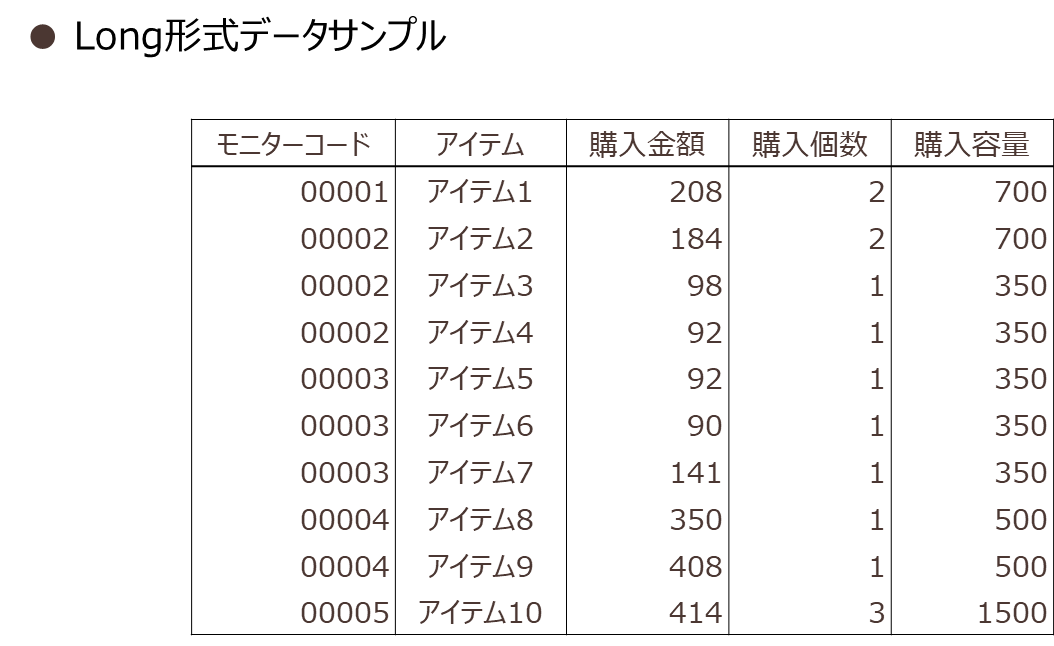
まずはデータ作成です。モニターごとに購買したアイテムについて集計し、各商品の購買個数、購買容量、購買金額を合計して表1のようなLong形式(縦持ち)ログデータセットを用意します。分析は東急エージェンシー社のTarget Finder®(※4)を利用して行いました。
図表2のデータを直接取り込み、Target Finder®内でBoW形式に変換し、PLSAを実行します。抽出するトピック数を情報量規準(AIC)をもとに探索し、今回は18トピックを抽出しました。
図表2
抽出したトピックの特徴を知るには、図表3のような各トピックにアイテムが所属する確率を示す潜在確率行列を解釈します。
図表3
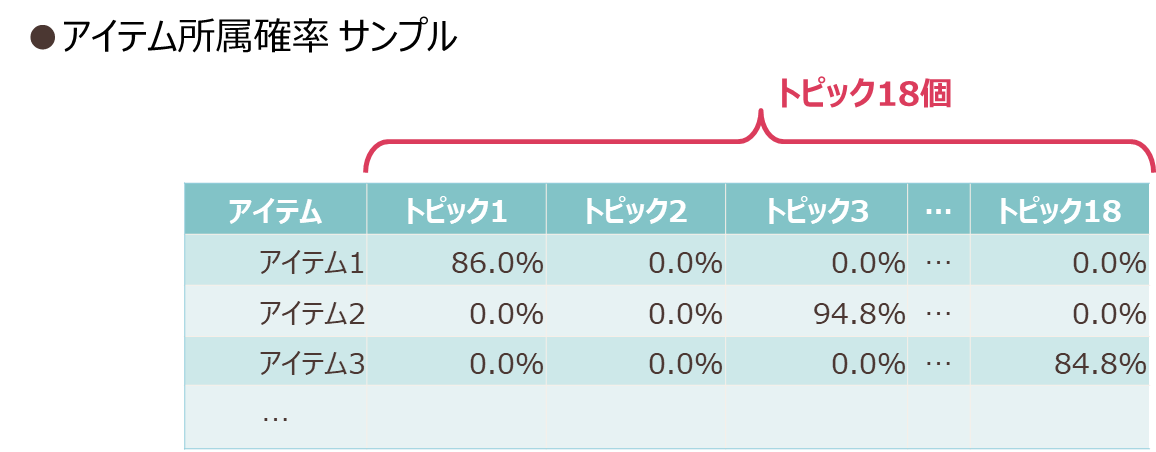
その結果、トピック1・3・7・8・10はアルコール度数が低いフルーツ風味のサワー・チューハイなどのアイテムが多くなりました。一方トピック4・6・11・15・17では比較的アルコール度数が高く、ウイスキー風味のアイテムが多く占めていました。
次に、モニターのクラスタリング結果を見てみます。図表4のような、各トピックにモニターが所属する確率を示す潜在確率行列を解釈します。
図表4
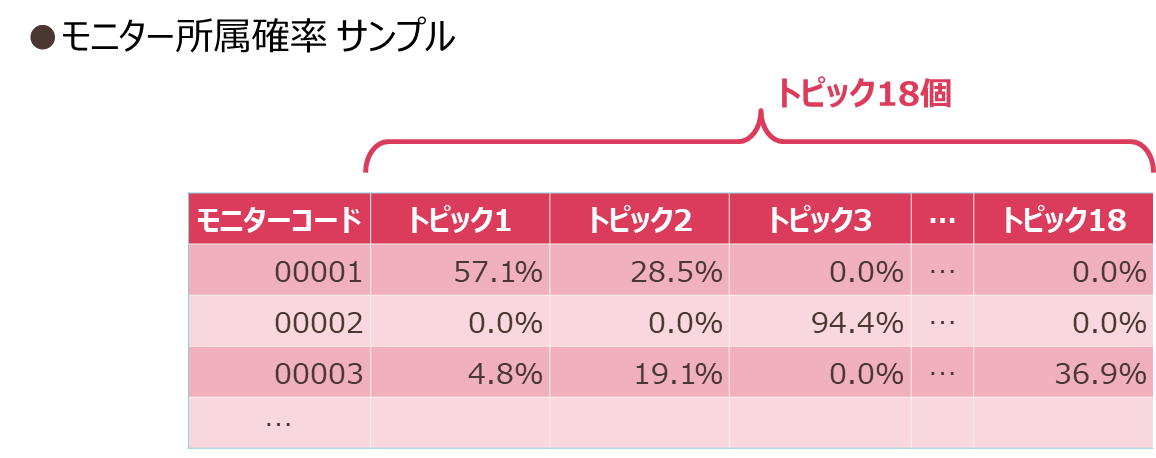
例えば、モニターコード00001の人はトピック1とトピック2に所属する確率が高いため、これらに含まれるアイテムの購入意向が強いと解釈できます。
さらに、各モニターを所属確率が最も高いトピックに紐づけて、性別・年代構成をみてみると、図表5のような内訳になります。
図表5
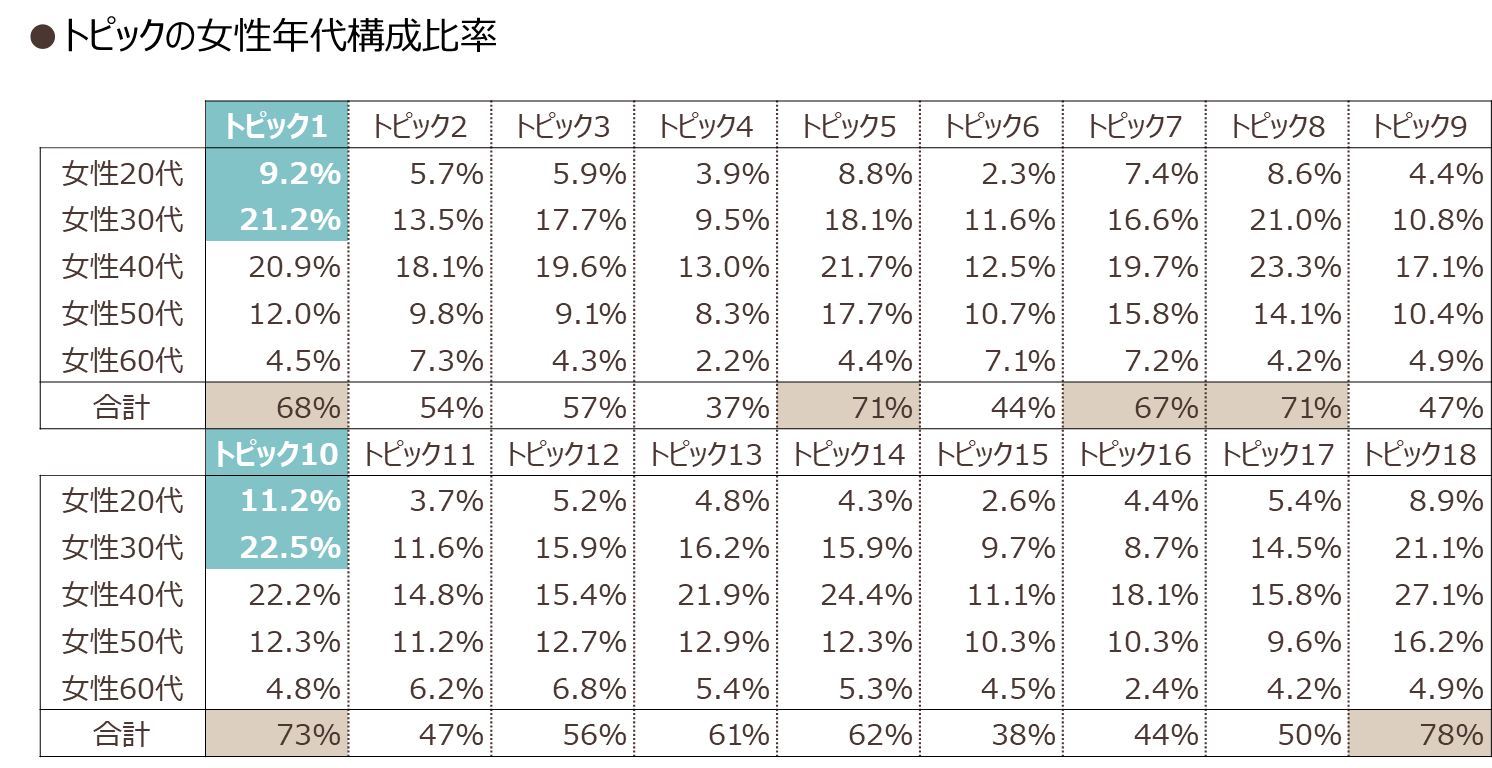
今回は女性飲用者をターゲットにするため、女性構成が多いトピックを確認します。すると、「トピック1」「トピック5」「トピック7」「トピック8」「トピック10」「トピック18」で女性の割合が65~75%となっていました。このうち、今回は20-30代女性の含有率が多いトピック1とトピック10それぞれへの所属確率が最も高い人をターゲットとして、分析をドリルダウンします。
今回は生活者360°viewer(※5)を使ってプロファイル分析を行いました。これによって消費者の価値観や行動を多面的に捉え、その特性や適切なマーケティングアプローチを明らかにしていきます。プロファイルの観点として、「飲酒頻度」「メディア接触」「消費意識」「消費行動」を取り上げます。
図表6にトピックごとの特徴をまとめました。
図表6

トピック1は流行に敏感で、新商品やサービスが出ると友人に伝えることが好きなため、クチコミによる拡散を期待できそうです。飲酒頻度も多く、新商品の飲料が出るたびにチェックをしているかもしれません。一方トピック10は、安定・倹約志向が強く、飲酒頻度も少ない層です。Webによる情報収集を行い、クチコミによる評判にも影響を受ける層でもあるため、ソーシャルメディアを活用して商品訴求していくことなどが有用かもしれません。
トピックモデルのマーケティングへの活用は、解釈と施策実行精度の双方を担保しています。さらにそこに生活者360°viewerといったプロファイリングと組み合わせることで、ターゲットの発見と消費者の特徴を理解したうえでのコミュニケーションプランを策定することが可能になります。
行動データに基づいた適切な消費者セグメンテーションや多面的にプロファイリングを行う技術は今後も有用なアプローチであるといえるでしょう。
※1:多次元からなる情報に対して、情報の本来の性質を保ったまま少ない次元の情報に落とし込むこと。
※2:確率的潜在意味解析。データの行列を分解することで潜在クラス(=トピック)を抽出する手法、LSA(Latent Semantic Analysis)に確率的処理を加えた手法。ただし、手元にあるデータからトピックを抽出するため、新規データのクラスを推定することができない。
※3:Latent Dirichlet Allocation。PLSAを拡張した手法。LDAでは確率的処理の際、ディリクレ分布という確率分布を仮定してトピックを生成する。このため、観測していない新規データに対しても推定が可能となる。
※4:PLSAを基に国立研究開発法人 産業技術総合研究所が開発したプログラムをベースに開発した分析ツール(https://www.tagc-solutions.com/product/target_finder/)。
※5:インテージが持つ、消費履歴、メディア接触状況、さらには生活意識・価値観など、さまざまなデータの連携により、多面的で多彩なターゲット増のプロファイリングを実現する分析サービス(https://www.intage.co.jp/service/services/database/360viewer/)。
インテージのデータ解析・予測サービス
最新のデータサイエンス技術と独自データを活用し、予測や最適化シミュレーションなど高度なデータ活用を実現します。

◆本レポートの著作権は、株式会社インテージが保有します。
下記の禁止事項・注意点を確認の上、転載・引用の際は出典を明記ください 。
「出典:インテージ 「知るギャラリー」●年●月●日公開記事」
◆禁止事項:
・内容の一部または全部の改変
・内容の一部または全部の販売・出版
・公序良俗に反する利用や違法行為につながる利用
・企業・商品・サービスの宣伝・販促を目的としたパネルデータ(*)の転載・引用
(*パネルデータ:「SRI+」「SCI」「SLI」「キッチンダイアリー」「Car-kit」「MAT-kit」「Media Gauge」「i-SSP」など)
◆その他注意点:
・本レポートを利用することにより生じたいかなるトラブル、損失、損害等について、当社は一切の責任を負いません
・この利用ルールは、著作権法上認められている引用などの利用について、制限するものではありません
◆転載・引用についてのお問い合わせはこちら






