

いまやマーケティング活動の意思決定に欠かせないアンケート調査の基本の調査プロセスや実施のコツについて、シリーズで解説します。
第4回のこの記事では、アンケート調査の結果をわかりやすく、まとめるための集計の方法とコツについて解説します。
第1回の「アンケート調査の主な目的と役割・企画前のチェックポイント」の記事へはコチラから
第2回の「課題設定~仮説構築~調査手法の選び方編」の記事へはコチラから
第3回の「対象者条件設定~アンケートの作り方編」の記事へはコチラから
第5回の「結果のグラフ表現とアンケート調査の活用事例」の記事へはコチラから
定量のアンケート調査の回答結果を読むには、一人一人の回答結果に対して集計という統計処理を施します。最も多く用いられる集計方法が単純集計とクロス集計の二つです。
単純集計は、回答した人数を分母にし、それぞれの選択肢を選んだ人の人数を分子にして割り算をすることで、選択肢を選んだ人の割合(パーセンテージ)を計算します。英語では「Grand Total」というので、「GT表」という言い方をすることも多いです。
回答した人の総数が200人で、選択肢Aを選んだ人が120人の場合、図表1の様に計算し、集計結果は6割もしくは60%となります。
図表1

アンケート結果の全体傾向を把握するにはとても有効な集計処理なので、最初に全ての設問の単純集計結果を確認するとよいでしょう。
もう一つのクロス集計は、分母を複数設定して、それぞれごとに選択肢を選んだ人の数を計算する処理方法です。
図表2のように、男性・女性それぞれについて、選択肢Aを選んだ人の割合、率を算出します。「アンケート調査の結果を性別間で比較する」といった場合に行います。
図表2

実際には選択肢は複数あるので、集計結果は図表3のようなクロス表で表現されます。
図表3
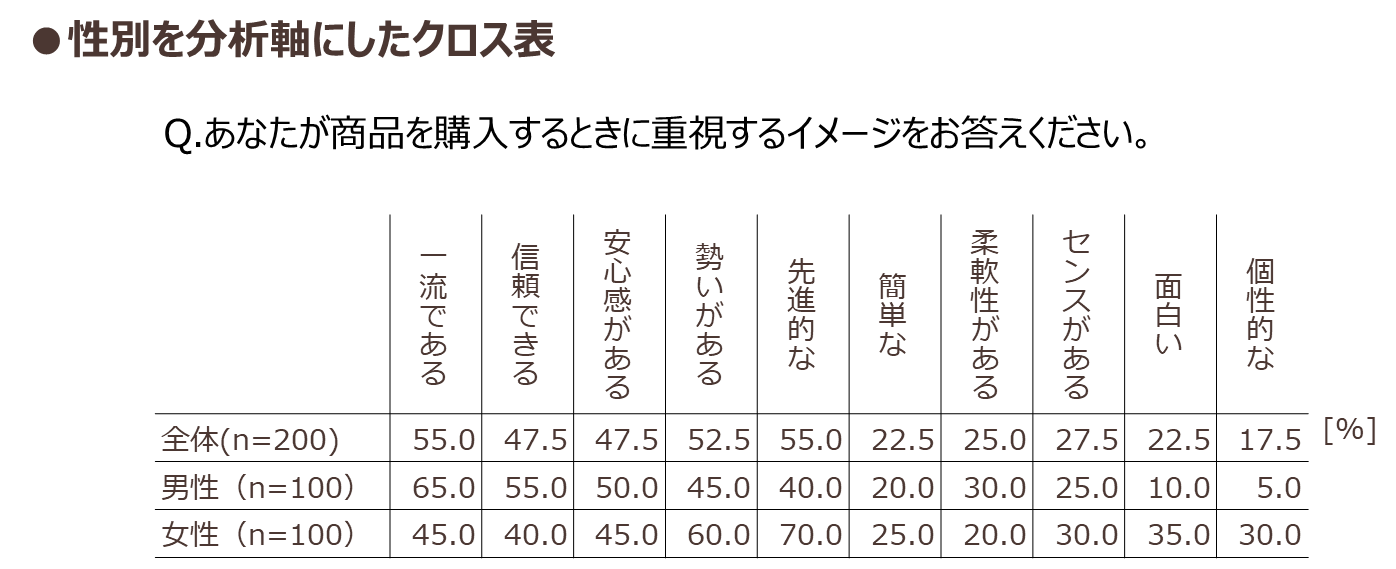
クロス表においては、左側にある項目を「表側」、上部にある項目を「表頭」と呼びます。また、表側にあたる性別はデータを分析する上で軸となる分類ですので、「分析軸」と呼びます。
この分析軸、実務的には性年代、職業といったデモグラフィック属性を用いて集計・分析することが多いのですが、選び方にコツがあります。マーケティング課題と関連する情報を分析軸とすることで、アンケート調査の結果を課題解決やマーケティングアクションに繋げる示唆が得られやすくなるのです。
例えば、
といった具合です。ただし、この分析軸は、実査が終わってから考えるものではありません。調査設計や調査票作成の時点で、分析軸として使う要素を盛り込んでおく必要があります。
集計結果を読み込む際の注意点として、サンプルサイズがあります。サンプルサイズは「男性」「女性」といった表側の項目あたりの回答者数にあたります。経験則的に分析軸のサンプルサイズが50サンプルを下回る場合は、数字のブレが大きくなりやすいので、項目間の数字の差の解釈には慎重になった方が良いでしょう。なお、分析に耐えうる最低サンプルサイズは30サンプルとする考え方も多いです。
データを集計し、結果をもとに分析を行う上で気を付けるべき点について説明します。
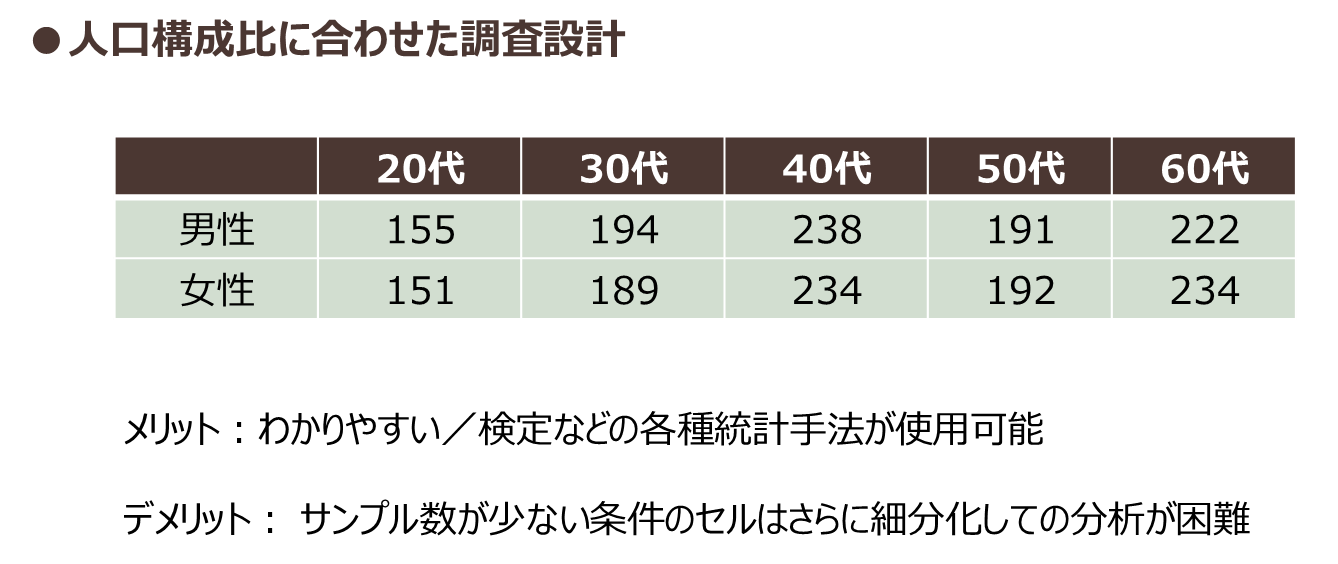
1つは、その調査で設計した「全体」が、「意味のある全体」をあらわさなくてはいけない、という点です。例えば、女性の20代から50代を10歳刻みで100人ずつを対象者として400人のアンケート調査を実施したとします。この調査における400人のデータは、「女性20代から50代の全体を表している」と考えてよいのでしょうか。
総務省統計局が6月に発表した「人口推計」によると、令和元年6月1日時点での女性20代は610万人、一方、女性50代は806万人です。女性50代は20代の1.3倍多いことが分かります。400人の調査結果を「女性の20代から50代の全体」として見たいのであれば、この世代間の人口ボリュームの差が調査設計に反映されている必要があります。
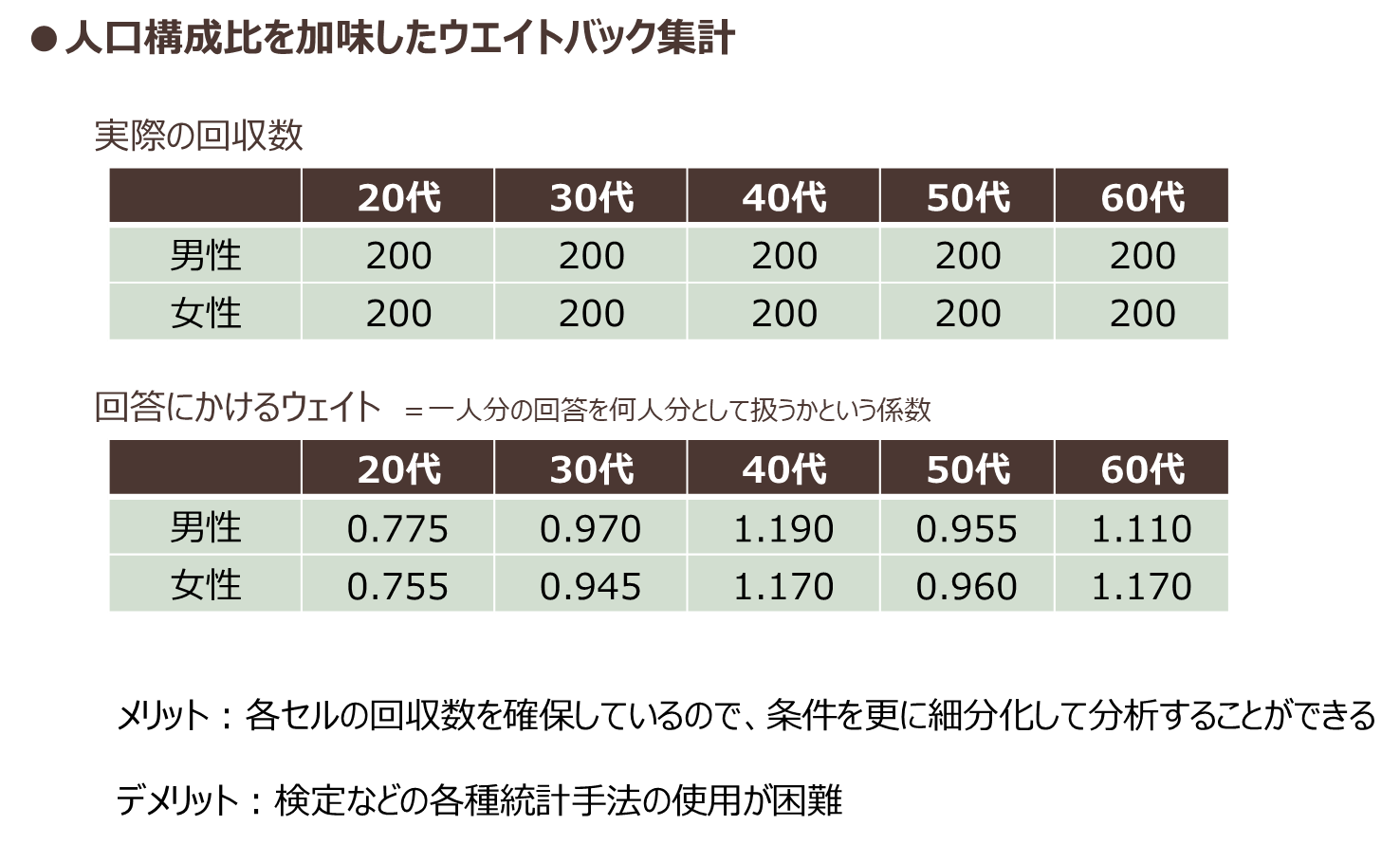
先ほど例に挙げた400人のアンケート調査は、女性20代も女性50代も100人と実際の人口構成比と異なっており、「女性20代から50代の全体を表している」とは言えません。調査結果の全体を「全体」として見るためには、調査を設計する段階でアンケート調査の年代ごとの回収数を人口構成比に合わせるか(図表4)、それぞれの年代の回答データに人口構成比に応じたウェイトを与えて集計する「ウェイトバック集計」を行う形で対応します。(図表5)
図表4
図表5
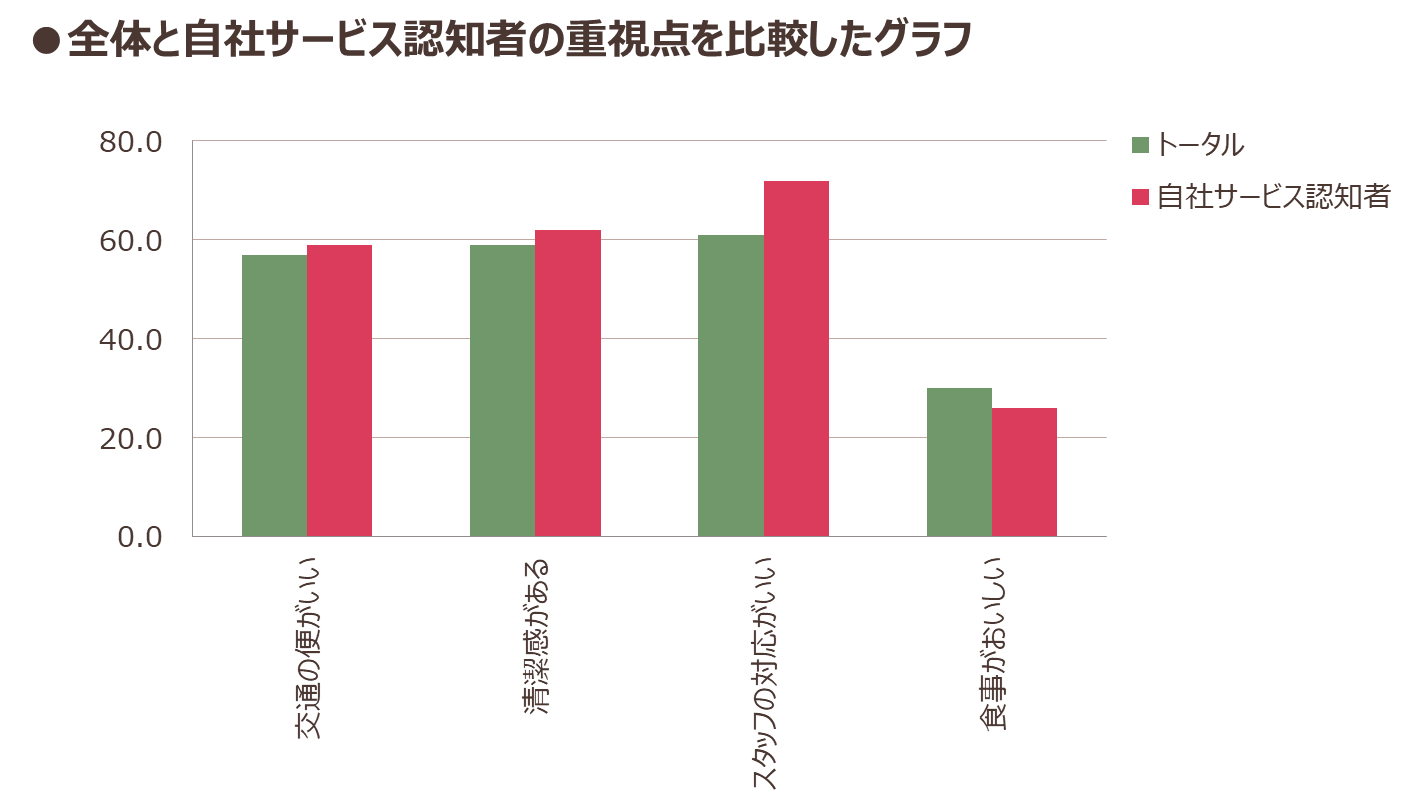
例えば「自社サービスの認知者の、サービスに対する重視点を知り、その特徴を明らかにしたい」とき、自社サービス認知者と市場全体のサービスユーザーで、重視点を比較してみると、図表6のようにあまり違いがないという結果になりました。
図表6
実はこの結果、市場全体のサービスユーザーに対し、自社サービスの認知者が大半を占めていたために起こっています。(図表7)
図表7

「自社サービス認知者」の特徴を明らかにするには、回答者の重なりがない「自社サービス認知者」以外の「自社サービス非認知者」と比較するといいでしょう。この比較対象については、「アンケート調査の方法とコツ③対象者条件設定~調査票作成編」で紹介したとおり、実査前に設計しておけば問題ありませんが、比較対象の選び方によって、知りたいことがわからないという落とし穴があることは、覚えておく必要があります。
回答結果を加工することで、結果を解釈しやすくしたり、さらに深い分析をすることができます。その方法をいくつかご紹介しましょう。
気持ちや意識の程度を「そう思う」から「そう思わない」といった気持ちの強弱を選択肢で表現して答えてもらう質問を「段階評価」といいます。図表8はその一例ですが、「そう思う」と「ややそう思う」(水色の網掛け)を合計し、少しでも当てはまる人の割合を捉えることで、調査結果の傾向が分かりやすくなります。
図表8
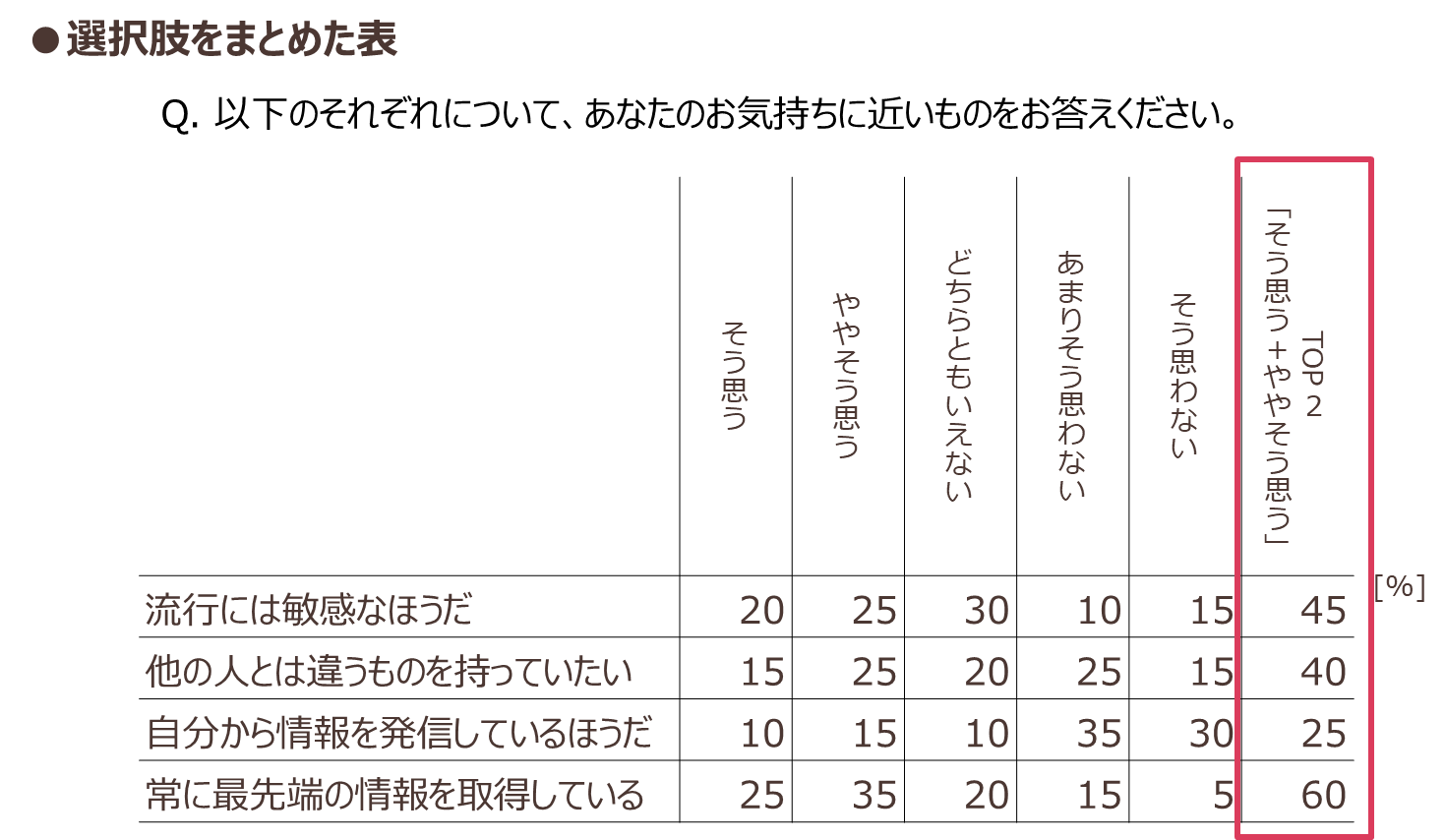
ただし、合算するということは元の情報の一部をそぎ落として要約するということなので注意が必要です。「商品を買いたいと思うか」という購入意向の段階評価などの場合は、「買いたい」と「やや買いたい」を合算して「買いたい」意向を示しているとの評価は少し甘い評価といえるでしょう。「やや買いたい」と答えた人の気持ちに嘘はありませんが、このような購入意向を測る5段階評価の解釈は「買いたい」と答えた人の率(トップボックス)を指標とすることが多いです。
例えば、ブランドのイメージはそのブランドの認知者に聴取しますが、集計のベースをブランドの所有者や使用者に絞り込むことで、イメージを「評価」として解釈することが出来ます。使用者が持っているイメージは、使用経験を反映した「イメージ」と考えられるからです。
調査項目間の関連性を整理する統計処理手法がいくつかあり、それらの集計手法を「多変量解析」といいます。なかでも、コレスポンデンス分析はよく用いる手法です。コレスポンデンス分析は、「複数のブランドとそれぞれのブランドが持っているイメージ」や「ユーザー属性と商品選びの重視点」などを分析するときに非常に便利な解析手法です。
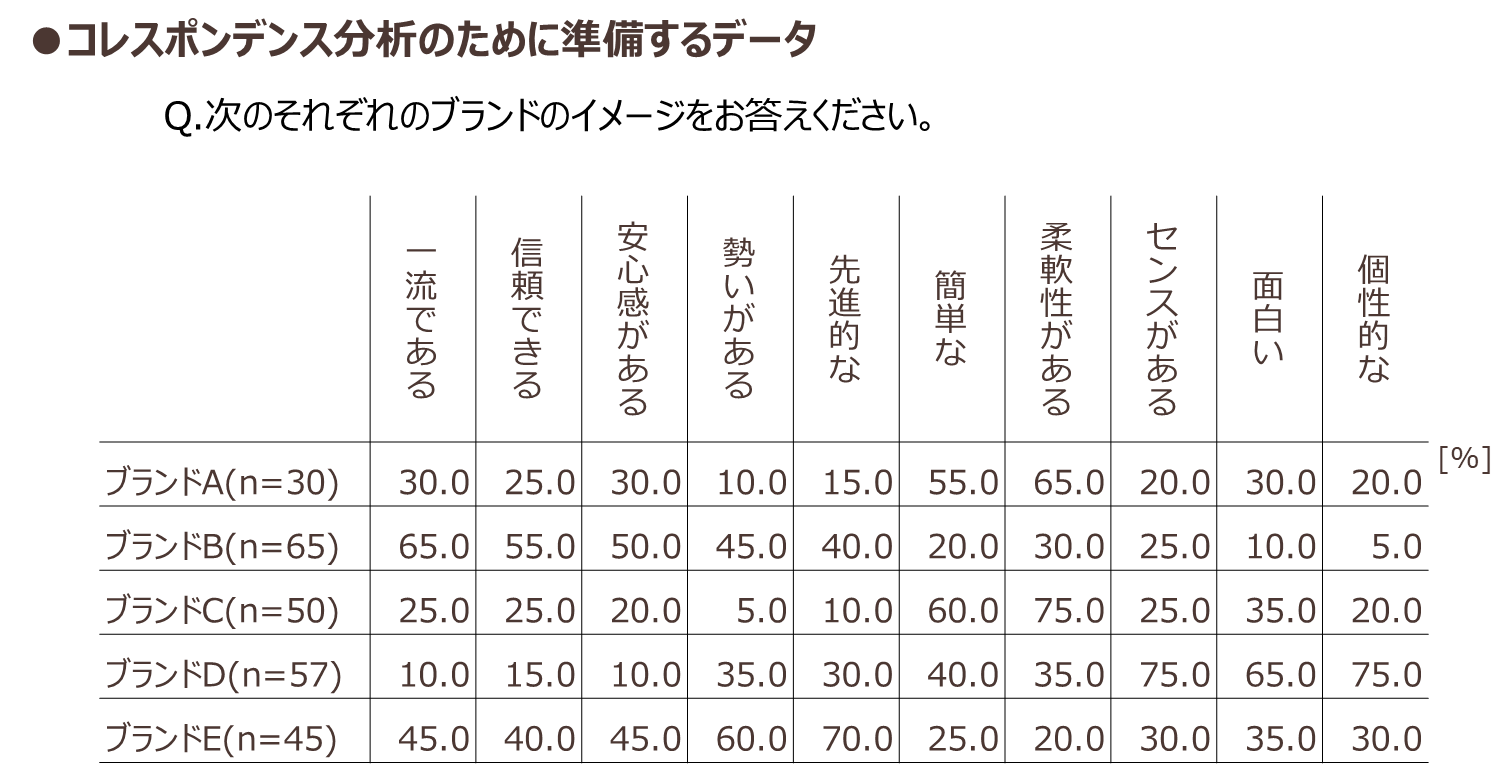
コレスポンデンス分析に必要なデータは図表9のように集計されたデータです。
図表9
図表9のデータをコレスポンデンス分析にかけた結果は、図表10のように二次元のマップ上にプロットできます。この例ではAからEの5つのブランドとブランドイメージの関係性を示しています。
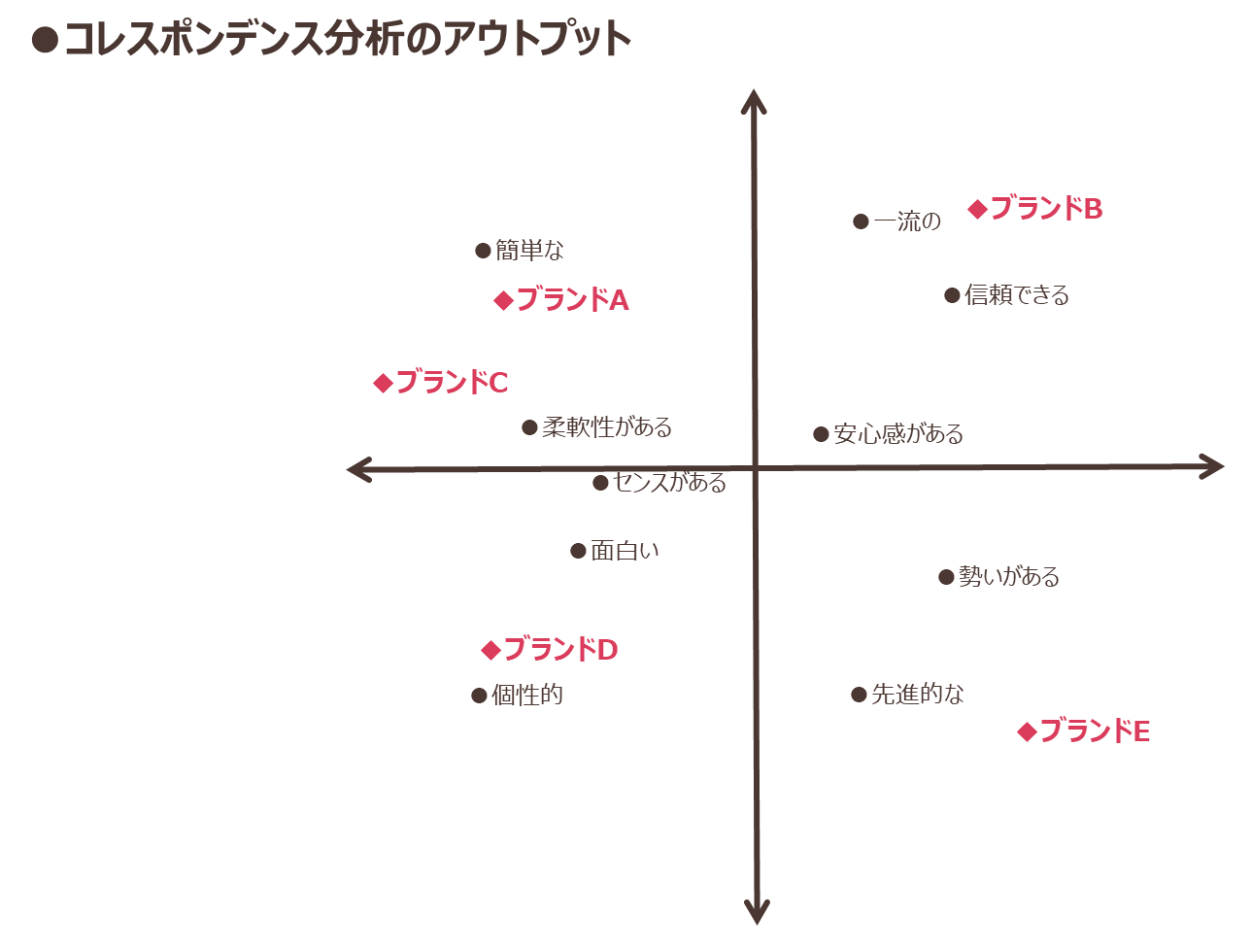
この図からはそれぞれのブランドがどのようなイメージを持たれているかということと、ブランド間のイメージの近さやポジションの独自性が視覚的にとらえられます。
例えばブランドBは「一流の」「信頼できる」「安心感がある」というイメージが、他のブランドと比較して強い、という解釈をすることが出来ます。同様に、ブランドAとブランドCは「簡単な」「柔軟性がある」という共通イメージを強く持った似たものブランドと解釈することが出来ます。
ただし、このような多変量解析のアウトプットは、たくさんあった元の情報の一部を切り捨てて特徴的な要素だけを抽出して表現しています。マップで傾向をつかんだら、必ず元になっている数表を読み込むことをお薦めします。
アンケートの回答形式には数字を答えてもらう形式や言葉や文章で答えてもらう形式もあります。その結果を読みやすくする方法を解説します。
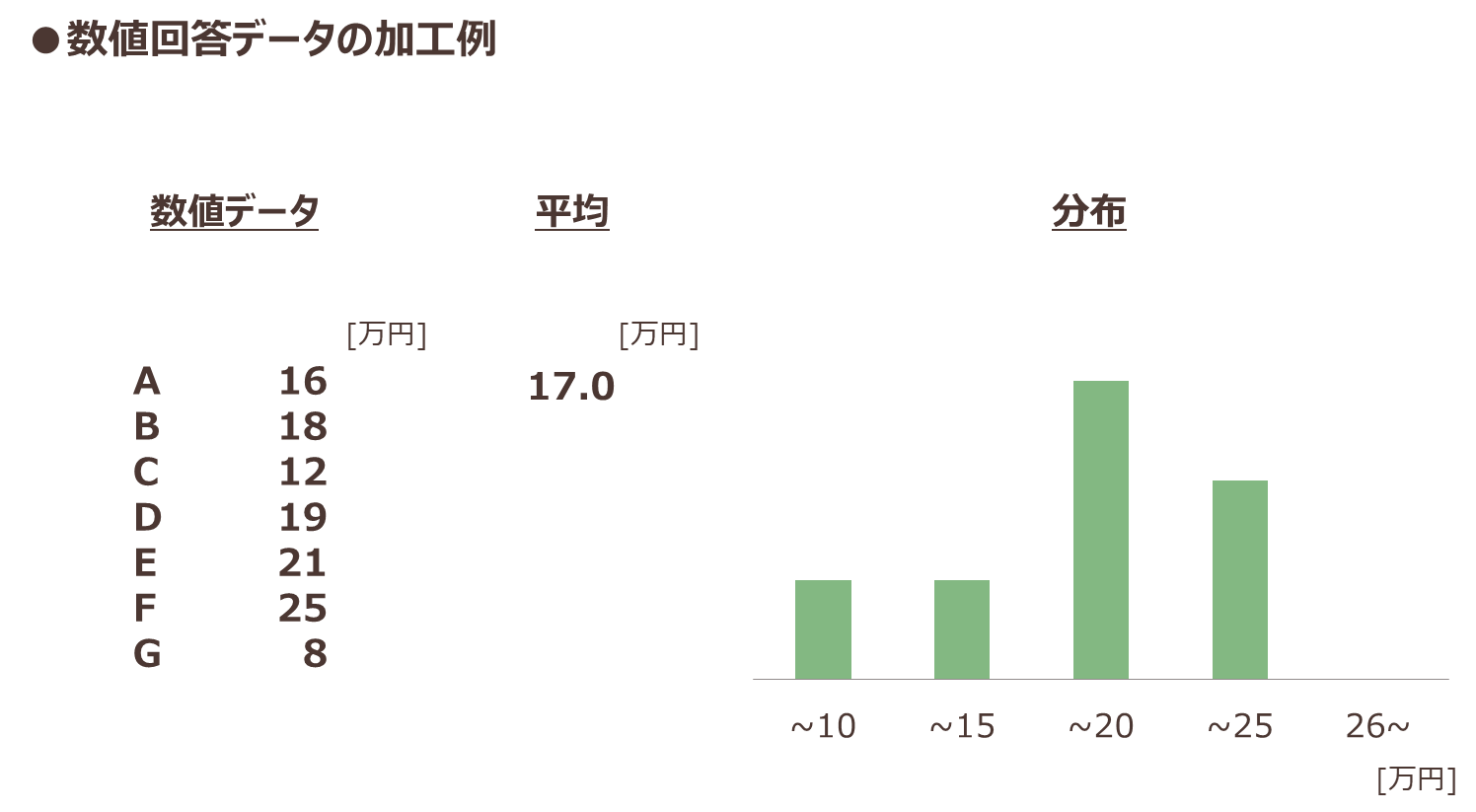
「1ヶ月の支出額」といった金額などを聴取するときには、数字で回答してもらうことがあります。といったような設問が該当します。アンケート結果は、そのまま平均を算出するといった処理も出来ますが、回答された数値の分布を見て、「〇円から〇円」といったカテゴリーを作成することで、その区分にあてはまる回答がどのくらいあるのか、といった構成比を確認できるようになります。
図表11
言葉で回答するタイプの設問(自由回答)には2通りあります。1つは単語単位で回答してもらうもので、「〇〇といったらどのようなブランドを思い浮かべますか」というように、カテゴリー情報以外は何も情報を提示せずにブランド名を思い浮かべてもらうタイプの設問です。これを純粋想起(非助成想起)といいます。このケースはテキスト情報に番号(カテゴリーコード)を振って選択肢として集計することで、ブランドごとの思い浮かべた人数が分かるようになります。
もう一つは文章を書いて回答してもらうものです。対象者が自分の言葉で表現している回答なので、処理などせずに読むことが望ましいのですが、特殊なツールを使用して「よく出てくる言葉」などを自動的に検出し、それらの関係性を捉える、といった探索的な分析をすることもあります。
大量に回答データから効率的に傾向をつかむ方法は、できるだけ多く使えるようにしたいものです。
今回は、集計結果を読むための集計処理の方法と使い方のコツを紹介しました。次回は、定量のアンケート調査の結果を報告書にまとめるときのグラフの選び方と、分析から得られる知見を複数の事例を元に解説します。
はじめてマーケティングネットリサーチを行う方向けに、押さえておくべきポイントを手元でご確認いただけるホワイトペーパーを作成しました。是非ダウンロードしてご活用ください。
◆本レポートの著作権は、株式会社インテージが保有します。
下記の禁止事項・注意点を確認の上、転載・引用の際は出典を明記ください 。
「出典:インテージ「知るギャラリー」●年●月●日公開記事」
◆禁止事項:
・内容の一部または全部の改変
・内容の一部または全部の販売・出版
・公序良俗に反する利用や違法行為につながる利用
・企業・商品・サービスの宣伝・販促を目的としたパネルデータ(*)の転載・引用
(*パネルデータ:「SRI+」「SCI」「SLI」「キッチンダイアリー」「Car-kit」「MAT-kit」「Media Gauge」「i-SSP」など)
◆その他注意点:
・本レポートを利用することにより生じたいかなるトラブル、損失、損害等について、当社は一切の責任を負いません
・この利用ルールは、著作権法上認められている引用などの利用について、制限するものではありません
◆転載・引用についてのお問い合わせはこちら






